本文最后更新于776 天前,其中的信息可能已经过时,如有错误请发送邮件到g1546780487@163.com
一、前言:
因为商科比赛和爬虫大作业而生的一堆代码。大部分参考自网络,欢迎学习复用。
但是不建议直接Ctrl+A Ctrl+C Ctrl+V 然后F5运行,这样大概率也运行不出来。
懂一点点Python的可能会看的很舒服。
参考文章:
爬虫百战(5)——使用自动化工具selenium爬取淘宝数据
https://www.codenong.com/cs106028364/
利用Python爬虫爬取淘宝商品做数据挖掘分析实战篇,超详细教程
https://www.zhihu.com/tardis/bd/art/34375874?source_id=1001
二、绕过反爬:
花里胡哨的,大多不太实用,手动扫个码最简单,毕竟咱也不是非要全自动。
import matplotlib
import matplotlib.pyplot as plt
import seaborn as sns
#一、爬虫数据搜集部分
from selenium import webdriver
from selenium.webdriver.common.by import By
#from selenium.webdriver.support.wait import WebDriverWait
import pandas as pd
import numpy as np
import time
keyword = '口红'
driver = webdriver.Chrome()
driver.get('https://s.taobao.com/search?q={}'.format(keyword))
time.sleep(15)
print('请在15s内完成扫码')
三、获取数据
driver.find_element(By.LINK_TEXT,"天猫").click()
time.sleep(5)
driver.find_element(By.LINK_TEXT,"销量").click()
time.sleep(5)
print("关键词为口红,按销量从高到低排序,仅选择天猫商品")
def get_datas(page_num):
data_lst = []
for j in range(1,page_num+1):
try:
for i in range(1,45):
try:
dic = {}
dic['img'] = driver.find_element_by_xpath(f'//*[@id="mainsrp-itemlist"]/div/div/div[1]/div[{i}]/div[1]/div/div[1]/a/img').get_attribute('src')
dic['标题'] = driver.find_element_by_xpath(f'//*[@id="mainsrp-itemlist"]/div/div/div[1]/div[{i}]/div[2]/div[2]').text
dic['店铺'] = driver.find_element_by_xpath(f'//*[@id="mainsrp-itemlist"]/div/div/div[1]/div[{i}]/div[2]/div[3]/div[1]/a/span[2]').text
dic['店家地址'] = driver.find_element_by_xpath(f'//*[@id="mainsrp-itemlist"]/div/div/div[1]/div[{i}]/div[2]/div[3]/div[2]').text
dic['产品售价'] = driver.find_element_by_xpath(f'//*[@id="mainsrp-itemlist"]/div/div/div[1]/div[{i}]/div[2]/div[1]/div[1]/strong').text
dic['付款情况'] = driver.find_element_by_xpath(f'//*[@id="mainsrp-itemlist"]/div/div/div[1]/div[{i}]/div[2]/div[1]/div[2]').text
print(dic)
data_lst.append(dic)
except:
print("数据采集失败")
num = driver.find_element_by_xpath('//*[@id="mainsrp-pager"]/div/div/div/div[2]/input')
num.clear()
num.send_keys(j+1)
driver.find_element_by_xpath('//*[@id="mainsrp-pager"]/div/div/div/div[2]/span[3]').click()
time.sleep(5)
print("已爬取{}页,程序休息.....{}s".format(j,5))
time.sleep(5)
except:
continue
print("一共获取{}条数据".format(len(data_lst)))
return(data_lst)
if __name__ == '__main__':
#driver = get_to_page('口红')
data_lst = get_datas(5)
#前两行是直接完成爬取淘宝中5页以口红为关键词搜索得到的商品信息数据
data = pd.DataFrame(get_datas(5))
data.to_excel('口红数据.xlsx',index=False)
#后两行是把获得的数据直接存放在本地
四、数据清洗
data = pd.read_excel('数据.xlsx')
data_anal = data[['店铺','店家地址','产品售价','付款情况']]
#处理缺失值
#对销量缺失值进行处理,此处采用取下一行数据的处理方式
data_anal['付款情况'].fillna(method = 'backfill',axis=0,inplace=True)
#提取店家省份
data_anal['地址'] = data_anal['店家地址'].apply(lambda x:str(x).split()[0])
data_anal.drop('店家地址',axis=1, inplace=True)
#提取销量
data_anal['销量'] = data_anal['付款情况'].apply(lambda x:str(x).split('+')[0])
data_anal.drop('付款情况',axis=1, inplace=True)
#把销量中的万转化为数字。
sales_list = list(data_anal['销量'])
for i in range(len(sales_list)):
sales_list[i]=str(sales_list[i])
if sales_list[i].rfind('万') > 0:
sales_list[i] = int(float(sales_list[i][0:sales_list[i].rfind('万')])*1e4)
else:
sales_list[i] = int(sales_list[i])
data_anal['销量'] = sales_list
data_anal.to_excel('清洗后数据.xlsx',index=False)
#data_anal['地址'] = data_anal['地址'].str.split(',',expand=True).replace('nan',np.nan)
#data_add_s = data_anal.dropna(axis=0).loc[:,['地址',"销量"]]
#data_add_s['地址'].value_counts().plot(kind='bar',color='steelblue')
五、数据分析——词云
#data_anal.dtypes
#3.1利用jieba 进行标题词云分析
#为jieba字典加入新词
import jieba
from PIL import Image
from wordcloud import WordCloud
jieba.add_word("唇釉")
jieba.add_word("唇泥")
jieba.add_word("唇露")
jieba.add_word("珂拉琪")
jieba.add_word("水雾")
jieba.add_word("水雾面")
jieba.add_word("哑光")
jieba.add_word("学生党")
jieba.add_word("防水")
jieba.add_word("小众")
jieba.add_word("水光")
title_list = list(data['标题'])
title_s = []
for line in title_list:
title_cut = jieba.lcut(line)
title_s.append(title_cut)
#导入停用词表
stopwords = pd.read_excel('stopwords.xlsx')
stopwords = stopwords.stopwords.values.tolist()
#剔除停用词
title_clean = []
for line in title_s:
line_clean = []
for word in line:
if word not in stopwords:
line_clean.append(word)
title_clean.append(line_clean)
#对每个list中的元素进行去重
title_clean_dist= []
for line in title_clean:
line_dist = []
for word in line:
if word not in line_dist:
line_dist.append(word)
title_clean_dist.append(line_dist)
#将 title_clean_dist 转化为一个单独单词的list: allwords_clean_dist
#并转化为数据框,同时删除空字符串
allwords_clean_dist = []
for line in title_clean_dist:
for word in line:
allwords_clean_dist.append(word)
df_allwords_clean_dist = pd.DataFrame({'allwords':allwords_clean_dist})
df_allwords_clean_dist = df_allwords_clean_dist.applymap(lambda x: np.where(x!=' ', x,None)).dropna()
#对最终过滤去重的词语进行分类汇总
word_count = df_allwords_clean_dist.allwords.value_counts().reset_index()
word_count.columns = ['word','count']
word_count = word_count[:80]
word_count.to_excel('关键词词频.xlsx',index=False)
word_count = pd.read_excel('关键词词频.xlsx',sheet_name=0,engine='openpyxl')
word_count_dict = word_count.set_index('word')['count'].to_dict()
#word_count_dict.pop('pinkbear')
#对标题进行词云绘制
font = r"C:\Windows\Fonts\simfang.ttf"
#plt.figure(figsize = (200,100))
mask = np.array(Image.open("ALICE2.png"))
w_c = WordCloud(font_path="simhei.ttf",
background_color="white",collocations=False,
width = 800,height = 600,max_words = 200,scale = 2,
contour_width = 4,contour_color = 'steelblue',
max_font_size =80,mask=mask)
wc =w_c.generate_from_frequencies(word_count_dict)
wc.to_file('关键词词频词云图.png')

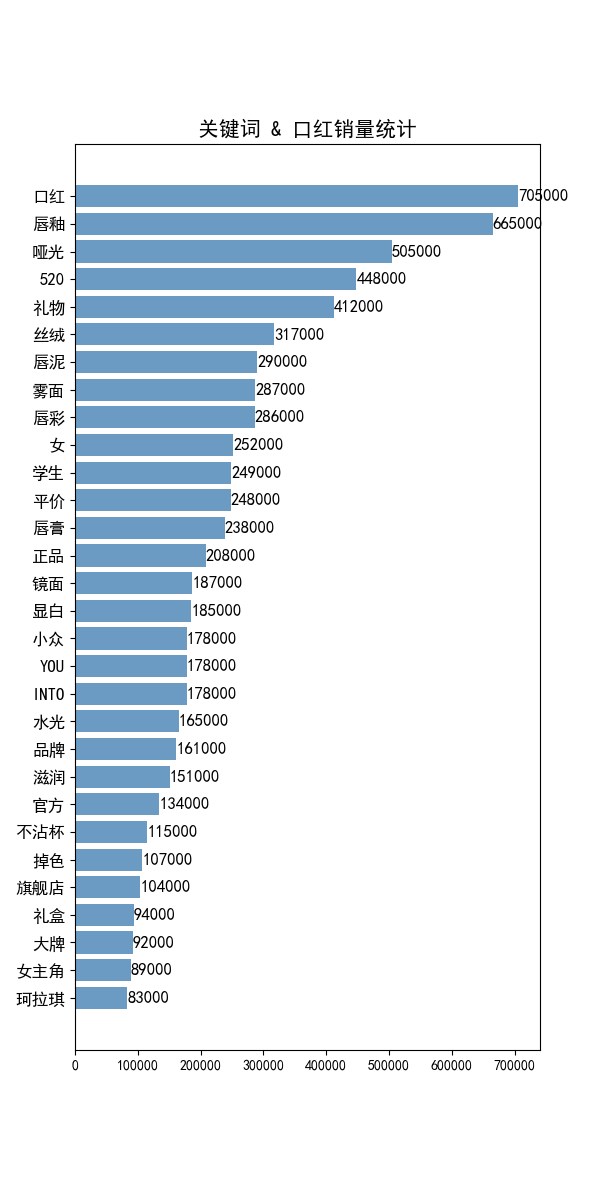
六、数据分析—— 不同关键词 对应 销量之和的统计分析
w_s_sum = []
word_count = df_allwords_clean_dist.allwords.value_counts().reset_index()
word_count.columns = ['word','count']
for w in word_count.word:
i = 0
s_list = []
for t in title_clean_dist:
if w in t:
s_list.append(data_anal['销量'][i])
i+=1
w_s_sum.append(sum(s_list))
df_w_s_sum = pd.DataFrame({'w_s_sum':w_s_sum})
df_word_sum =pd.concat([word_count,df_w_s_sum],axis=1,ignore_index = True)
df_word_sum.columns = ['word','count','w_s_sum']
#取销量最高的30行关键词
df_word_sum.sort_values('w_s_sum',inplace =True,ascending= True)
df_w_s = df_word_sum.tail(30)
#绘图
font = {'family':'SimHei'}
matplotlib.rc('font',**font)
index = np.arange(df_w_s.word.size)
plt.figure(figsize=(6,12),dpi=100)
plt.barh(index,df_w_s.w_s_sum,color='steelblue',align='center',alpha=0.8)
plt.yticks(index,df_w_s.word,fontsize=12)
plt.title('关键词 & 口红销量统计',fontsize=15)
#添加数据标签
for y,x in zip(index,df_w_s.w_s_sum):
plt.text(x,y,'%.0f' %x ,ha='left',va='center',fontsize=12)
plt.savefig('关键词 & 口红销量统计.png')
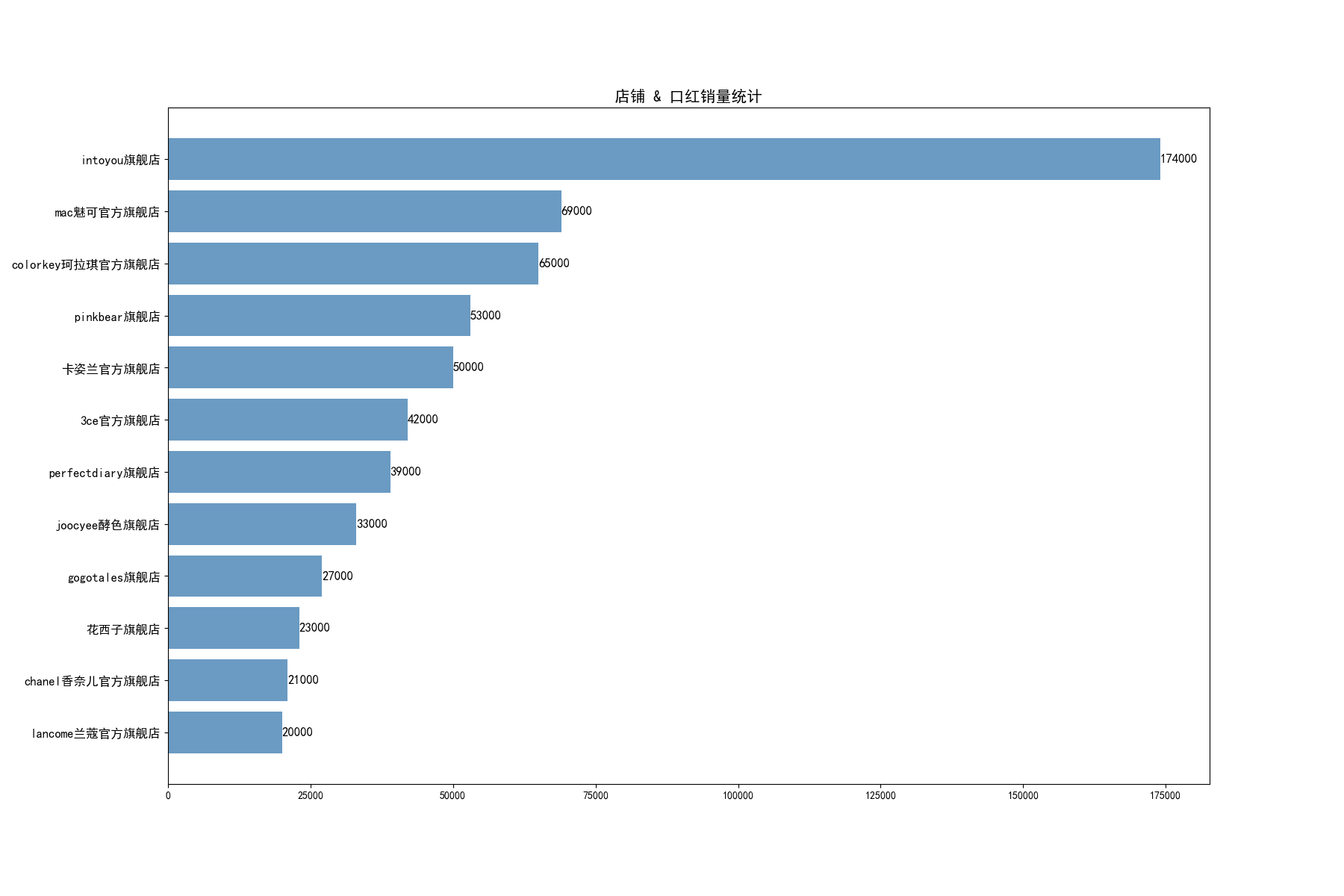
七、数据分析—— 不同店铺 对应 销量之和的统计分析
df_c_s_sum = data_anal.loc[:,['店铺',"销量"]]
df_c_s_sum = df_c_s_sum.groupby('店铺').sum() #相同店铺销量相加
df_c_s_sum = df_c_s_sum.sort_values(by=['销量'],ascending=True) #按降序排序
df_c_s = df_c_s_sum.tail(12) #取销量排行前12
#绘图
font = {'family':'SimHei'}
matplotlib.rc('font',**font)
index = np.arange(df_c_s.size)
plt.figure(figsize=(18,12),dpi=100)
plt.barh(index,df_c_s['销量'],color='steelblue',align='center',alpha=0.8)
plt.yticks(index,df_c_s.index,fontsize=12)
plt.title('店铺 & 口红销量统计',fontsize=15)
#添加数据标签
for y,x in zip(index,df_c_s['销量']):
plt.text(x,y,'%.0f' %x ,ha='left',va='center',fontsize=12)
plt.savefig('店铺 & 口红销量统计.png')
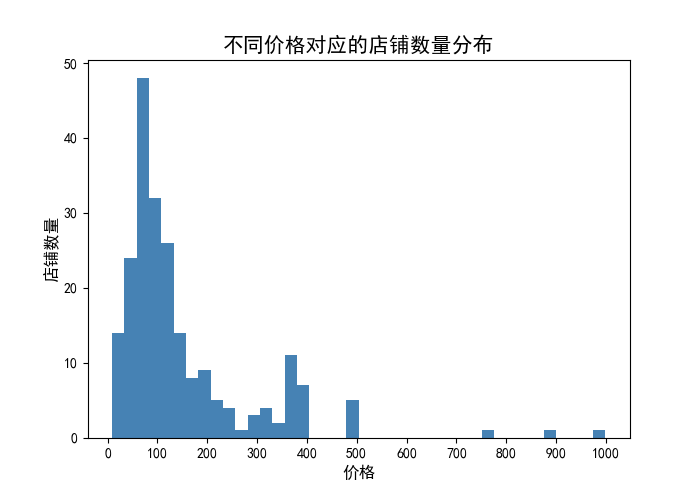
八、数据分析—— 不同价格对应的店铺数量分布
#data_p = data_anal[data_anal['产品售价']<600]
data_p = data_anal['产品售价'].to_frame()
plt.figure(figsize=(7,5),dpi=100)
plt.hist(data_p['产品售价'],bins=40,color='steelblue')
plt.xlabel('价格',fontsize = 12)
plt.xticks(np.arange(0,1100, step=100))
plt.ylabel('店铺数量',fontsize = 12)
plt.title('不同价格对应的店铺数量分布',fontsize = 15)
plt.savefig('不同价格对应的店铺数量分布.png')
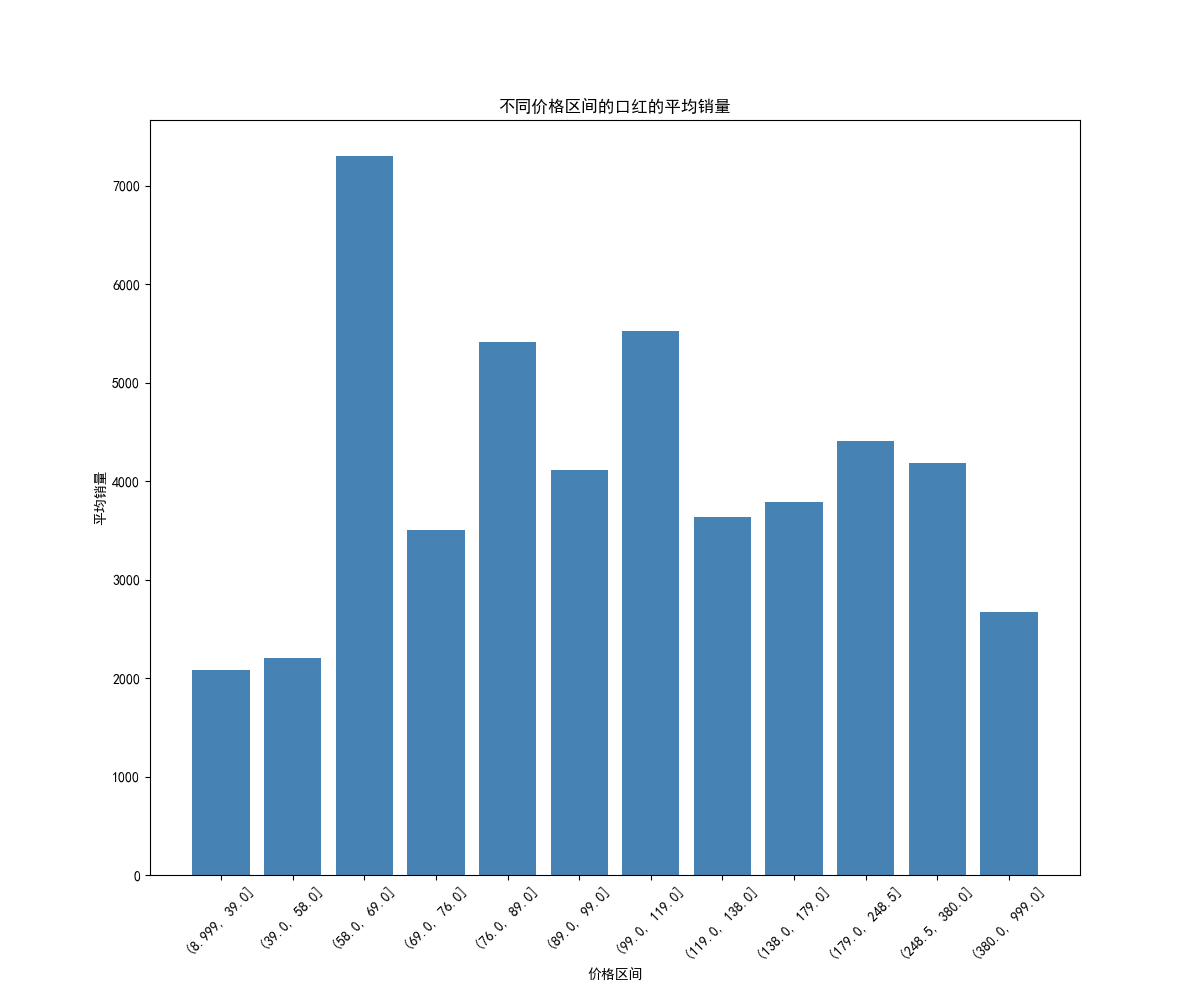
九、数据分析—— 不同价格区间口红的平均销量
data_anal['产品售价'] = data_anal['产品售价'].astype('int')
#把价格区间分为12组
data_anal['group'] = pd.qcut(data_anal['产品售价'],12)
df_group = data_anal.group.value_counts().reset_index()
#计算分组后每一价格区间的销量均值
df_s_g = data_anal[['销量','group']].groupby('group').mean().reset_index()
#绘制柱形图
index = np.arange(df_s_g.group.size)
plt.figure(figsize=(12,10),dpi=100)
plt.bar(index,df_s_g['销量'],color='steelblue')
plt.xticks(index,df_s_g.group,fontsize=10,rotation=45)
plt.xlabel('价格区间')
plt.ylabel('平均销量')
plt.title('不同价格区间的口红的平均销量')
plt.savefig('不同价格区间的口红的平均销量.png')
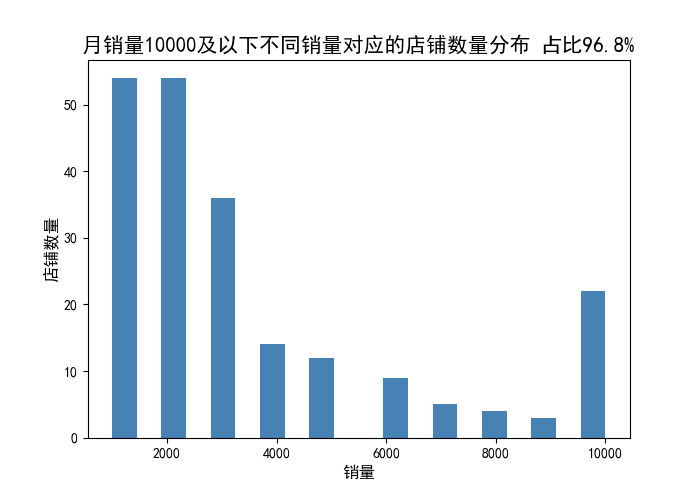
十、数据分析—— 月销量10000以下不同销量对应的口红商品数量分布
data_s = data_anal['销量'].to_frame()
data_s = data_anal[data_anal['销量']<=10000]['销量'].to_frame()
print('月销量10000及以下的商品占比:%.3f' %(len(data_s)/len(data_anal)))
plt.figure(figsize=(7,5),dpi=100)
plt.hist(data_s['销量'],bins=20,color='steelblue')
plt.xlabel('销量',fontsize = 12)
plt.ylabel('店铺数量',fontsize = 12)
plt.title('月销量10000及以下不同销量对应的商品数量分布 占比96.8%',fontsize = 15)
plt.savefig('月销量10000及以下不同销量对应的商品数量分布.png')
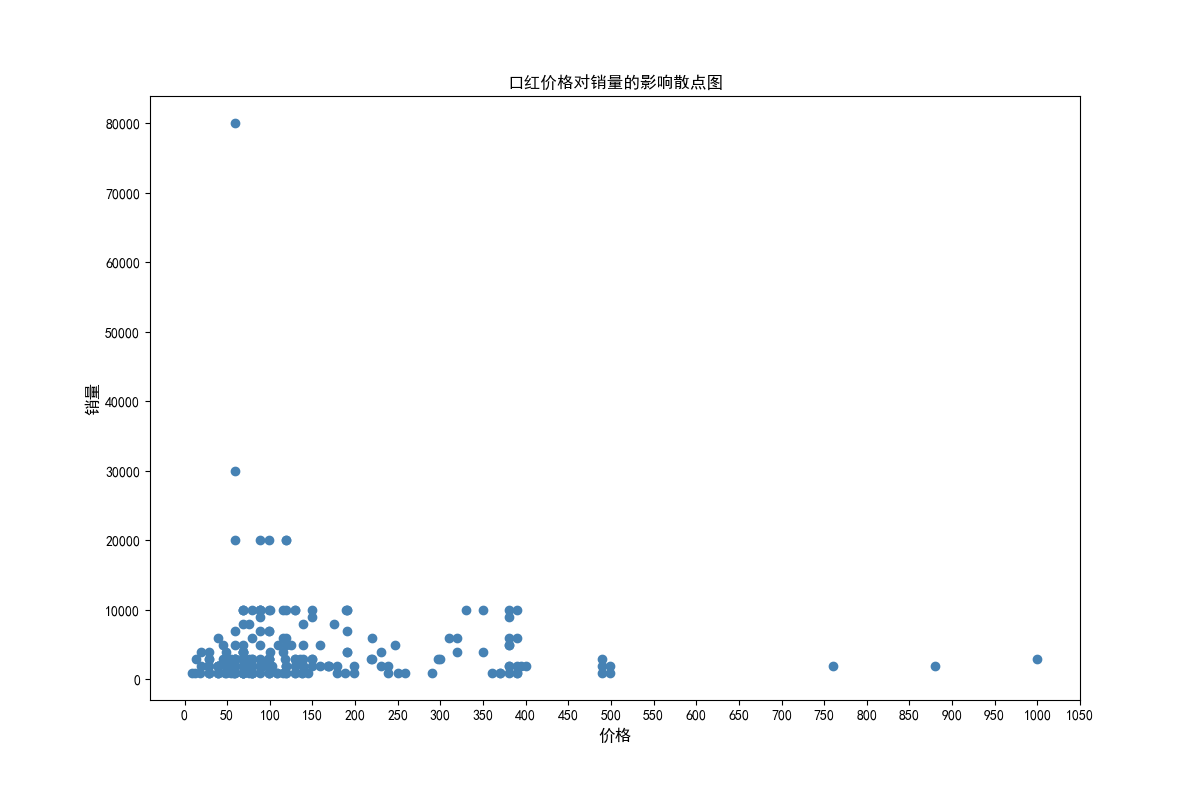
十一、数据分析—— 口红价格对销量的影响散点图分析
data_p = data_anal['产品售价'].to_frame()
data_s = data_anal['销量'].to_frame()
plt.figure(figsize=(12,8),dpi=100)
plt.scatter(data_p['产品售价'],
data_s['销量'],color='steelblue')
plt.xlabel('价格',fontsize = 12)
plt.xticks(np.arange(0,1100,step=50))
plt.ylabel('销量',fontsize = 12)
plt.title('口红价格对销量的影响散点图')
plt.savefig('口红价格对销量的影响散点图.png')
data_p_s = data_anal[data_anal['产品售价']<500]
data_p_s = data_p_s.loc[:,['产品售价',"销量"]]
#fig,ax = plt.subplots()
plt.figure(figsize=(12,8),dpi=100)
plt.scatter(data_p_s['产品售价'],
data_p_s['销量'],color='steelblue')
plt.xlabel('价格',fontsize = 12)
plt.xticks(np.arange(0,600,step=50))
plt.ylabel('销量',fontsize = 12)
plt.title('500元以下口红价格对销量的影响散点图')
plt.savefig('500元以下口红价格对销量的影响散点图.png')
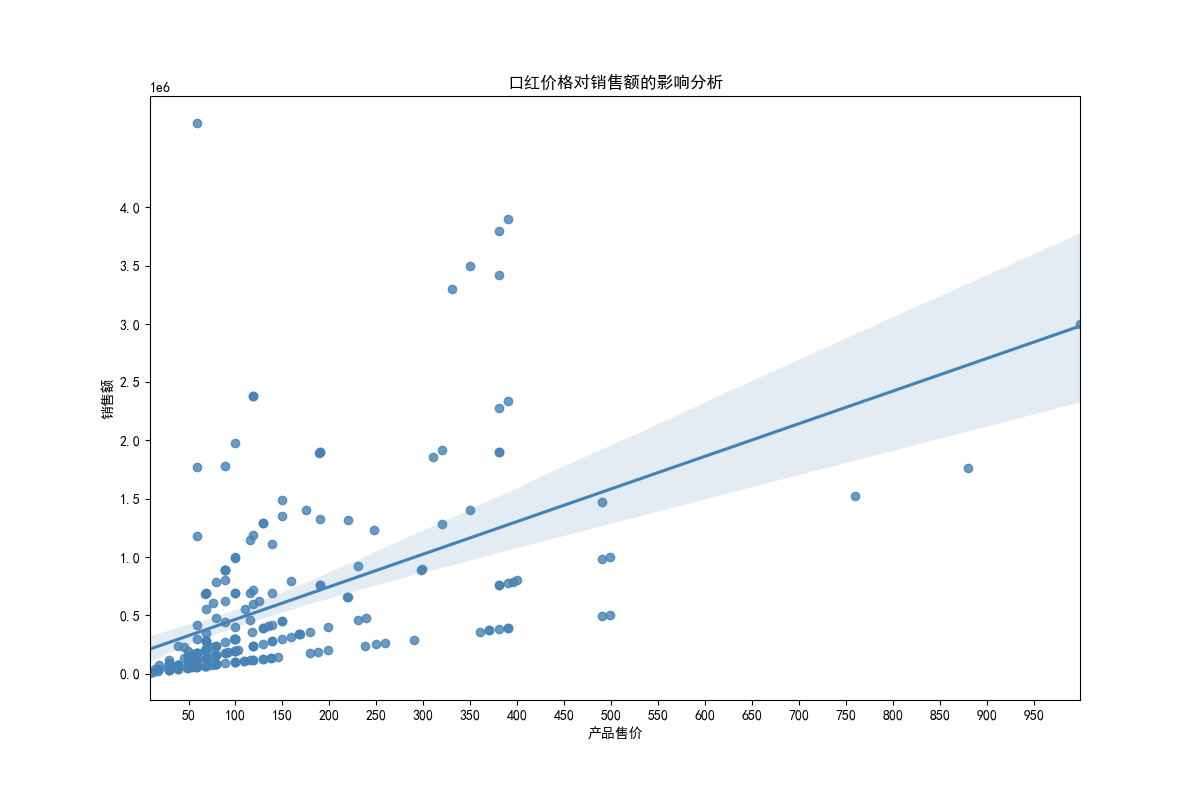
十二、数据分析—— 口红价格对销售额的影响分析:
data_anal['销售额'] = data_anal['产品售价'] * data_anal['销量']
plt.figure(figsize=(12,8),dpi=100)
plt.xticks(np.arange(0,1100,step=50))
plt.yticks(np.arange(0,4500000,step=500000))
plt.title('口红价格对销售额的影响分析')
sns.regplot(x='产品售价',y='销售额',data=data_anal,color='steelblue')
plt.savefig('口红价格对销售额的影响分析.png')
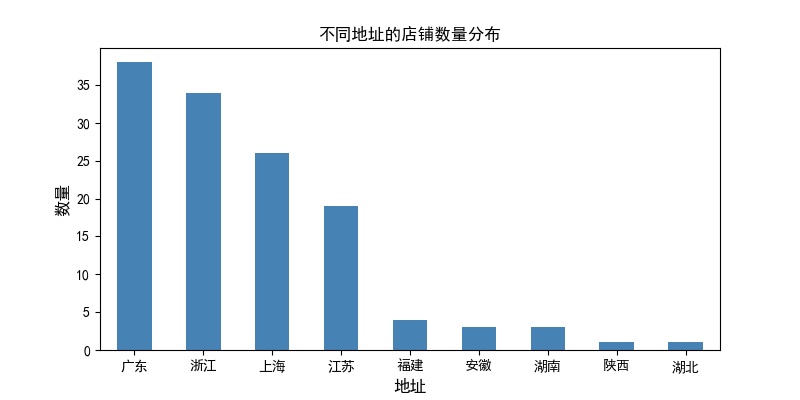
十三、数据分析—— 不同地址的店铺数量分布:
plt.figure(figsize=(8,4),dpi=100)
data_anal['地址'] = data_anal['地址'].str.split(',',expand=True).replace('nan',np.nan)
data_add_s = data_anal.dropna(axis=0).loc[:,['地址',"销量"]]
data_add_s['地址'].value_counts().plot(kind='bar',color='steelblue')
plt.xticks(rotation=0)
plt.xlabel('地址',fontsize = 12)
plt.ylabel('数量',fontsize = 12)
plt.title('不同地址的店铺数量分布')
plt.savefig('不同地址的店铺数量分布.png')
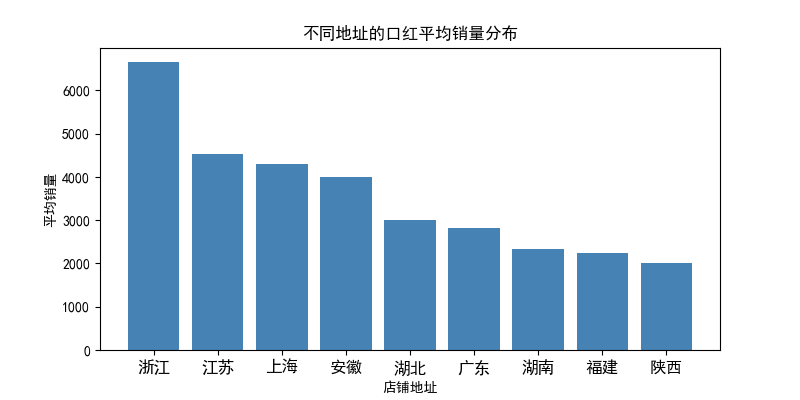
十四、数据分析—— 不同地址的口红平均销量分布:
add_sales = data_add_s.pivot_table(index = '地址',values='销量',aggfunc=np.mean) #分类求平均
add_sales.sort_values('销量',inplace =True,ascending = False)
add_sales = add_sales.reset_index()
index = np.arange(add_sales['销量'].size)
plt.figure(figsize=(8,4),dpi=100)
plt.bar(index,add_sales['销量'],color='steelblue')
plt.xticks(index,add_sales['地址'],fontsize=12,rotation=0)
plt.xlabel('店铺地址')
plt.ylabel('平均销量')
plt.title('不同地址的口红平均销量分布')
plt.savefig('不同地址的口红平均销量分布.png')